
来源:DeepTech深科技
尽管大语言模型已经在许多任务中表现出色,但它们在超出训练集分布泛化方面的能力仍然未被充分理解。例如,在自然语言处理中,大语言模型在某些泛化任务中的确表现优异,但在其他任务中可能会产生事实性错误或误导性信息。
近日,上海人工智能实验室徐兴成研究员与包括上海科技大学张海鹏、赵梓博以及复旦大学杨燕青在内的合作者,通过一套统一的理论框架阐明了基于 Transformer 的语言模型在不同算术场景中的泛化机制,并揭示了任务属性和训练数据对于模型表现的决定性作用。这能帮助人们更好地理解模型泛化行为,还为更高效的数据训练以及更优的人工智能对齐提供指导。
首先,本次成果将能指导模型训练优化。通过对训练数据质量和覆盖范围加以分析,可以更好地理解向内和向外泛化的影响,从而优化训练数据的选择和使用,同时还能节省数据资源。此外,通过对任务属性进行分析,可以帮助设计与模型属性相容的结构,从而提升模型的向外泛化能力。
其次,本次成果将能用于自然语言处理研究。即将泛化理论用于自然语言处理中的复杂任务分析,使其能够更准确、更高效地处理各种语言任务。
再次,本次成果将能用于人工智能对齐与安全提升。通过深入理解大语言模型在不同任务中的泛化机制,可以设计出更加安全、更加可控的人工智能系统。
 图 | 徐兴成(来源:徐兴成)
图 | 徐兴成(来源:徐兴成)围绕泛化性,研究人员试图弄清:为什么不同任务之间会存在差异?在失败的任务中大语言模型究竟学到了什么?在成功的任务中大语言模型又是如何实现有效泛化的?
由于直接在自然语言任务开展探索受到数据复杂性、内外分布界定困难性以及评估标准不明确的制约,他们选择以算术任务作为研究模型泛化行为的重要途径。这些任务具有很好的数学结构和评价标准,提供了分析和理解泛化现象的理想环境。以此,他们希望回答几个关键问题:
首先,为什么在某些任务中,模型可以在合适的位置编码下正确地执行更长的未见算术任务(比如加法),而在更复杂的任务(比如乘法)中的效果却不尽如人意?
其次,为什么无论使用何种位置编码,模型在特定模数下(例如模 100)对于更长的未见模运算表现良好,而在非常接近的模数下(例如模 101)却表现不佳?
此前的研究者们通过各类实验,也发现了各种看似无关的分布外泛化现象,却缺乏统一理论。为了克服“盲人摸象’的困境,该课题组找到了一个统一分析框架,用以探索和揭示这些分布外泛化现象背后的统一理论。
基于此,他们定义和发现了向内分布外泛化概念和向外分布外泛化概念,从而让诸多长度泛化问题变得清晰起来。
同时,他们也发现了训练数据在向内泛化中和向外泛化中所扮演的不同角色,从而能够帮助人们理解训练数据覆盖范围对于模型泛化性能的影响。
另外,这一过程也让研究人员意识到任务属性对于模型表现差异的重要影响,从而回答了模型如何才能学会加法。
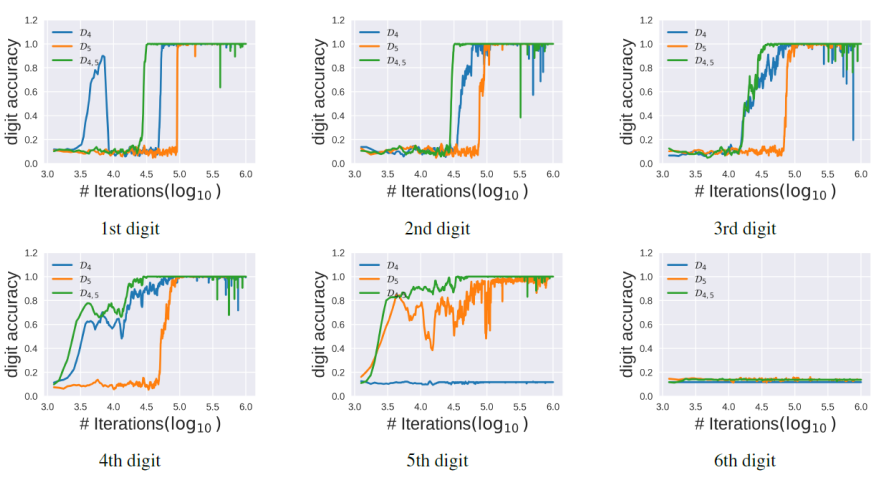 图 | 绝对位置编码语言模型在加法任务中的逐位测试准确率(来源:arXiv)
图 | 绝对位置编码语言模型在加法任务中的逐位测试准确率(来源:arXiv)后续,他们计划进一步深化对大语言模型泛化性的理解,并探索其在其他任务中的应用。
其一,将扩展到更复杂的任务,包括自然语言处理中的复杂语义理解、逻辑和因果推理等。
其二,将探索多模态模型的泛化性。
其三,将打造高效的数据训练方法。他们希望以此减少模型训练对大规模数据集的依赖,并提高模型在数据不足时的泛化能力。
其四,将实现人工智能对齐与安全。即利用研究人员对于泛化机制的理解,来增强人工智能系统的安全性和可靠性。
该团队补充称,他们也期望在人工智能的发展过程中引入更多的理论基础,从而减少试探性方法所带来的不确定性。他们相信通过集体的智慧和努力,未来的人工智能系统将更智能、更可靠。
参考资料:
1.https://arxiv.org/pdf/2407.17963
排版:初嘉实
训练人工智能

 新浪科技公众号
新浪科技公众号 “掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)
 相关新闻
相关新闻 
